
Автор: Лимонов Алексей
Источник: RSDN Magazine #1-2005
Опубликовано: 22.05.2005
Исправлено: 07.09.2005
Версия текста: 1.0
Практическое применение
Заключение
Введение
Обработка и хранение символьных данных на сервере MS SQL 2000 осуществляется при помощи схем сопоставления (collation). Схемы содержат шаблоны каждого символа, правила сортировки и сравнения. В предыдущих версиях сервера MS SQL необходимо было отдельно указывать кодовую страницу и порядок сортировки символьных данных, причем эти настройки действовали сразу на все объекты сервера. В MS SQL 2000 схемы сопоставления позволили более гибко подходить к работе с текстовыми данными. В данной статье рассматриваются основные принципы работы схем, а также их применение в российских условиях.
Назначение collation
Символьные данные
В машинном представлении любой символ или знак представляет различные комбинации битов. Соответственно, использование одного байта для хранения символа дает возможность определить до 256 различных символов. Если увеличить объем данных до двух байт, появится возможность распознавать 65 536 символов.
Кодовая страница есть ни что иное, как набор различных комбинации состояний битов (всего 256) в байтовой структуре. Эти комбинации определяют символы верхнего и нижнего регистров, цифры, специальные символы. При переносе данных между компьютерными системами с различными кодовыми страницами необходимо выполнить преобразование. Символы, битовая комбинация которых отсутствует в схеме назначения, в результате будут потеряны.
Для устранения подобных ситуаций международная организация стандартов ISO и группа Unicode разработали стандарт Unicode.
Порядок сортировки определяет правила сравнения и представления символов. Например, символ «а» больше символа «б». Кроме того, порядок сортировки устанавливает правила сопоставления символов верхнего и нижнего регистров.
Описание схем сопоставления
Схемы сопоставления collation определяют способы хранения и обработки символьных данных сервера. Каждая схема устанавливает:
- порядок сортировки для данных с кодировкой Unicode;
- порядок сортировки для данных с кодировкой не-Unicode;
- кодовую страницу для данных с кодировкой не-Unicode.
Для MS SQL 2000 не надо указывать все три параметра, достаточно выбрать имя схемы и порядок сортировки.
На сервере реализованы две группы схем – Windows collations и SQL collations. Первая группа схем сопоставления реализована на сервере для поддержки региональных настроек Windows. Рекомендуется работать именно с этой группой. Вторая группа, SQL collations, используется для совместимости с предыдущими версиями сервера MS SQL. Ее выбор может быть оправдан, если вы планируете обмениваться данными с серверами MS SQL 6.5 или MS SQL 7.0, или если приложение, работающее с данными, разработано с учетом схем сопоставления предыдущих версий сервера.
На разных уровнях могут использоваться различные схемы сопоставления:
- Уровень сервера. Схема сопоставления выбирается при установке сервера. Выбранная схема будет использована по умолчанию для всех системных баз и пользовательских баз данных, а также всех объектов каждой базы. При необходимости изменить схему на уровне сервера используется утилита Rebuild Master.
- Уровень базы данных. Схему сопоставления можно указать при создании базы. Все объекты базы будут использовать эту схему по умолчанию. Также выбранная схема будет использоваться для символьных переменных и параметров. Изменить схему сопоставления базы данных можно при помощи команды ALTER DATABASE.
- Уровень поля таблицы. При создании таблицы можно указать собственную схему сопоставления.
На уровне объектов базы (таблиц) схема не указывается.
Практическое применение
Как ни странно, на схемы сопоставления, как и на триггеры, часто не обращают должного внимания. Точнее – о схемах вспоминают только во время возникновения ошибки «Cannot resolve collation conflict». Для решения возникающих проблем необходимо понимать причины их возникновения и пути их возможного решения.
Рассмотрим вариант работы на ОС Windows 2000 Server с региональными настройками Russian. При установке MS SQL 2000 программа предлагает установить схему collation Cyrillic_General_CI_AS. Первая часть схемы «Cyrillic_General» определяет кодовую страницу. Далее идут правила сортировки, например, CI (case-insensitive) – нечувствительная к регистру, AS (accent-sensitive) – чувствительная к ударению. Можно получить полный список схем сопоставления с расшифровкой, выполнив запрос
При выборе Cyrillic_General_CI_AS все системные базы данных, в том числе база TempDB, будут использовать именно эту схему сравнения. Как указано выше, все вновь создаваемые пользовательские базы и таблицы по умолчанию будут иметь точно такую же схему. Однако ничто не мешает при установке выбрать другую схему и так же с ней работать.
Когда вы работаете в рамках одной структуры collation, проблем не возникает. Чаще всего они появляются, когда вы присоединяете или устанавливаете базу с другой схемой сопоставления. В большинстве случаев это схема SQL_Latin1_General_CP1251_CI_AS. Она представляет собой схему сопоставления вида SQL collations, доставшуюся в наследство от версии MS SQL 7.0. К примеру, указанная схема устанавливается, если вы выполняете обновление сервера или переносите БД с версии MS SQL 7.0 на MS SQL 2000. Здесь следует отметить, что хоть по смыслу схемы SQL_Latin1_General_CP1251_CI_AS и Cyrillic_General_CI_AS схожи, на самом деле для сервера это различные схемы сопоставления. И при их одновременном использовании сложно избежать ошибок.
Для примера рассмотрим ситуацию, когда сервер установлен с collation Cyrillic_General_CI_AS, есть база данных NEW_BASE с серверной схемой сопоставления Cyrillic_General_CI_AS, и база данных OLD_BASE для работы со старым приложением со схемой SQL_Latin1_General_CP1251_CI_AS. За базу NEW_BASE можно не беспокоиться – в рамках серверной схемы сопоставления все запросы будут корректно обрабатывать символьные данные. Другое дело, когда необходимы данные из OLD_BASE.
Ошибка «Cannot resolve collation conflict» будет появляться:
- При соединениях JOIN или UNION с таблицами из базы с другой схемой сопоставления.
- При работе с временными таблицами в контексте рабочей базы данных. Временные таблицы создаются в базе TempDB, где, как было уже отмечено, используется серверная схема сопоставления, и символьные данные в этом случае корректно сравнить не удается.
- Самый общий случай – когда пытаются сравнить значения символьных полей разных схем сопоставления (даже в пределах одной таблицы или базы данных).
Сообщение об ошибке говорит само за себя – сервер не в состоянии сравнить символы из различных схем сопоставления. Решение напрашивается следующее: привести данные к одной схеме collation.
Если в запросах к БД OLD_BASE идет работа с временными таблицами, либо переменными табличного типа, то при их создании надо явно указывать нужную схему collation для каждого символьного поля. Например:
Далее, выполнить соединение между полями с различными схемами напрямую нельзя. Соответственно, нельзя сделать JOIN или UNION для таблиц с различными схемами collation из одной или разных баз. Иначе опять будет выдано сообщение об ошибке. В этом случае объединяемые поля также необходимо привести к одной схеме при помощи преобразования схемы сопоставлений. Допустим, соединение таблиц OLD_BASE и NEW_BASE можно выполнить так:
а запрос на объединение так:
Преобразование схем сопоставления полей можно делать в различных вариантах соединений. Но писать каждый раз подобные запросы, с явным указанием схемы collation – не самое лучшее времяпровождение. Тогда можно рассмотреть вариант приведения всех баз к единой схеме – серверной. Для изменения схемы collation, используемой в БД по умолчанию, служит команда
Однако это еще не изменит схему для символьных полей в базе. Менять их нужно либо вручную через Enterprise Manager, либо написать подобный запрос:
При этом имеется ряд ограничений – нельзя изменить схемы для вычисляемых полей, индексированных полей, полей с ограничением CHECK или внешних ключей. Необходимо вначале удалить их, а после изменения схемы сопоставления заново создать. Так что работа здесь может быть проделана большая и серьезная.
Если вы не в состоянии привести новую базу к серверной схеме, и у вас нет возможности менять код в приобретенном приложении – надо менять серверную схему и схему всех ваших баз данных (опять-таки, если это не приведет к остановке работы других приложений и баз). Самый надежный и простой способ замены серверной схемы – переустановка всего сервера, что в принципе равносильно использованию утилиты Rebuild Master. После этого надо воссоздать структуры баз (но не данные в них!) уже с новой схемой collation, затем импортировать данные в обновленную структуру.
Если старая БД привязана к определенной схеме collation, а новая база использует иную схему, то остается один способ – поставить новый сервер или установить именованный экземпляр (instance) SQL-сервера. Правда, еще не ясно, сколько уйдет ресурсов на реализацию именованной установки сервера, и поддерживает ли приобретенное приложение вообще такую конфигурацию. Вполне возможно, что проще будет установить отдельный сервер со своей схемой collation на отдельной машине.
Заключение
Как вы могли убедиться – выбор схемы сопоставления может существенно повлиять на разработку и сопровождение серверных решений. Поэтому необходимо определится с оптимальным выбором схемы collation на начальном этапе в соответствии с требованиями существующих приложений и стратегией развития системы в целом.

После перехода версию платформы 1С 8.3.4 и выше зачастую появляется сообщение подобного содержания:
Ошибка СУБД:
Microsoft SQL Server Native Client 10.0: Cannot resolve the collation conflict between «Cyrillic_General_CI_AS» and «SQL_Latin1_General_CP1251_CI_AS» in the equal to operation.
HRESULT=80040E14, SQLSrvr: SQLSTATE=42000, state=9, Severity=10, native=468, line=10
Данная ошибка появляется только на клиент-серверной версии MS SQL Server. Связано это с тем, что начиная с релиза 8.3.4 технологическая платформа 1С учитывает еще и региональные настройки программы.
Исправление
Collation — это схема сопоставления, в которой содержатся правила сортировки и сравнения символов в базе данных. Ранее, по умолчанию(«Latin1_General»), в документации 1С нигде не было указаний по установке правильного параметра «collation», теперь же при установке SQL сервера необходимо это учитывать.
Изменить этот параметр представляется возможным только в версии MS SQL 2000 (запрос — ALTER DATABASE «ИмяБд» COLLATE «НоваяКодировка»). В остальных версиях изменение возможно только rebuild’ом, то есть по сути переустановкой СУБД.
При переустановке необходимо обратить внимание на соответствующий параметр в установщике:
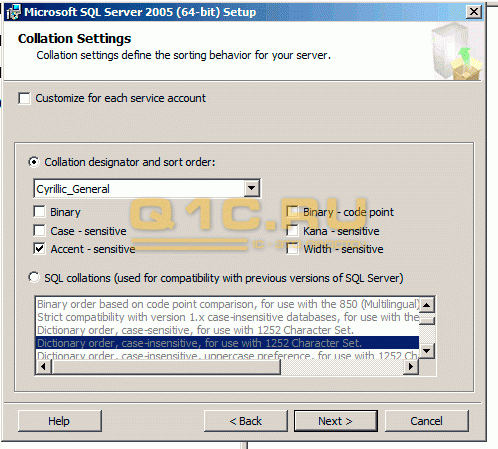
К сожалению, мы физически не можем проконсультировать бесплатно всех желающих, но наша команда будет рада оказать услуги по внедрению и обслуживанию 1С. Более подробно о наших услугах можно узнать на странице Услуги 1С или просто позвоните по телефону +7 (499) 350 29 00. Мы работаем в Москве и области.
I’m generating a XML file with PHP using DomDocument and I need to handle asian characters. I’m pulling data from the MSSQL2008 server using the pdo_mssql driver and I apply utf8_encode() on the XML attribute values. Everything works fine as long as there’s no special characters.
The server is MS SQL Server 2008 SP3
The database, table and column collation are all SQL_Latin1_General_CP1_CI_AS
I’m using PHP 5.2.17
Here’s my PDO object:
My query is a basic SELECT.
I know storing special characters into SQL_Latin1_General_CP1_CI_AS columns isn’t great, but ideally it would be nice to make it work without changing it, because other non-PHP programs already use that column and it works fine. In SQL Server Management Studio I can see the asian characters correctly.
Considering all the details above, how should I process the data?
detector
