
Мы уже говорили, что использование векторных и матричных обозначений делает очень похожими, но крайней мере внешне, уравнения векторные и матричные на обычные скалярные уравнения. Мы этим сходством пользовались, например, в теореме существования и единственности для системы

когда оказалось, что достаточно повторить доказательство скалярной теоремы, заменив модуль на норму.
Совершенно аналогичной оказалась ситуация и с линейными уравнениями, когда использование фундаментальной матрицы Ф(?) позволило записать общее решение однородной и неоднородной системы в виде

Эти формулы практически идентичны формулам для решения скалярного уравнения.
Теперь мы немножко поговорим о системе с постоянными коэффициентами

и о соответствующем матричном уравнении

Последнее уравнение настолько похоже па обычное скалярное х = ах. решением которого является обычная экспонента х = ce at , что возникает естественный соблазн воспринимать решение матричного уравнения как экспоненту от матрицы.
Мы уже говорили (когда обсуждали комплексную экспоненту), что вычисление экспоненты на любом новом множестве объектов (что комплексных чисел, что матриц, что дифференциальных операторов неважно) в любом случае должно аксиоматизироваться. То есть экспонента полагается „по определению* 4 равной некоторому выражению, а вот оправданность такого определения необходимо обсуждать. Оправдание определения не доказательство, а, наоборот, вывод из него свойств, которые аналогичны свойствам обычной экспоненты. Чем больше удастся сохранить свойств тем более оправданным является определение.
Кроме того, часто приходится из нескольких эквивалентных вариантов выбирать какой-то один. Обычно стараются выбрать тот, который позволяет обосновывать остальные свойства проще, с меньшими выкладками.
В случае экспоненты от матрицы наиболее подходящим определением оказывается представление в виде ряда.
Определение 22.1 Экспонентой от матрицы А называется матрица 

Это определение удобно тем, что не требует никаких дополнительных конструкций, кроме сложения и умножения матриц (эти операции мы выполнять умеем) и предельного перехода во множестве матриц, который, но существу, является предельным переходом в пространстве IRnxn пространстве наборов из п 2 чисел. Правда, чисел хитро расположенных в виде матрицы, и поэтому мы, в зависимости от удобства, можем интерпретировать этот предельный переход либо как покомпонентный, либо как предел в смысле нормы матриц.
Перечислим основные свойства матричной экспоненты.
Свойство 1. Определение 22.1 применимо к любой матрице А.
Действительно, ряд, фигурирующий в определении, мажорируется числовым рядом [1]

и поэтому сам является сходящимся к некоторой матрице. Соответственно ряд для e tA будет сходиться равномерно и абсолютно на любом конечном промежутке изменения t.
Свойство 2. Попробуем найти производную от e tA . Поскольку ряды, вообще говоря, почленно не дифференцируются, а только интегрируются. дифференцирование ряда осуществляют хитрой процедурой: пишут формальный ряд из производных, исследуют его сходимость, если он сходится интегрируют его почленно и получают, естественно, исходный ряд. И тогда уже с уверенностью утверждают, что ряд, составленный из производных, является на самом деле производной от исходного ряда. Поступим так и мы. Формальный ряд из производных имеет вид

и отличается от исходного ряда лишь множителем А

Поскольку умножение ни любой постоянный (не зависящий от п) множитель не меняет сходимости ряда, полученный ряд будет сходящимся равномерно на каждом конечном промежутке изменения t. Значит, почленное интегрирование полученного ряда допустимо, а оно дает как раз исходный ряд. Значит, производная исходного ряда равна

Это и есть второе свойство, наиболее важное для дифференциальных уравнений. Определенная нами матричная экспонента оказалась решением матричного дифференциального уравнения

Свойство 3. При t = О получаем е о л = I.
Свойство 4. Для любой фундаментальной матрицы матричного уравнения X = АХ (или векторного уравнения х = Ах) имеет место формула 
Действительно, в силу формулы общего решения матричного дифференциального уравнения любое решение (в том числе и наша экспонента) представима в виде e tA = Ф где С некоторая постоянная матрица. Используя свойство 3, получаем, что С = Ф -1 (0).
Свойство 5. dete = e i tr ‘ 4 . Это следствие из формулы Якоби (интеграл равен tl+t2 > A = e tlA e tiA (мультипликативное свойство экспоненты).
Доказательство этого свойства состоит в простом сравнении ряда для левой части

и произведения рядов в правой части

Поскольку в левой части мы имеем разложение по степеням матрицы А, удобно и правую часть представить в таком же виде. Для этого мы используем правило, позволяющее раскрывать скобки при умножении абсолютно сходящихся матричных рядов, и уже применявшуюся нами процедуру свертки.

Как мы видим, первое и второе слагаемые в обоих рядах совпадают. Третье слагаемое в ряде для e^ 1+t2 ^ равно ^(t+t2) 2 А 2 , а в полученном нами ряде для произведения экспонент

т.е. и здесь совпадение полное. Рассмотрим коэффициенты при А п . В ряде для экспоненты суммы он равен ^2) n ; а в ряде для произведения экспонент 

В полученной сумме мы без труда узнаем формулу бинома Ньютона (ведь биномиальные коэффициенты С? как раз равны п/[к <п —А)!]). Таким образом, и в общем случае все сходится: коэффициент при А п в разложении экспоненты от суммы и в разложении произведения экспонент совпадают.
Свойство 7. Решение неоднородной системы х = Ах + /(?), удовлетворяющее условию x(to) = ф определяется формулой

Это свойство является прямым следствием предыдущего и формулы для решения задачи Коши (22.12). Если в качестве Ф(?) взять как раз e tA . то

Свойство 8. e tA = lim (I + -А) п . Доказывается, как и свойство 6,
прямыми вычислениями. Отметим, что близкая к указанной формула 
выражающая экспоненту через так называемую резольвенту матрицу Я(А) = (/ — АЛ) -1 , используется для построения не только экспоненты от матрицы, но и экспоненты от дифференциальных операторов. Если А заменить дифференциальным оператором, то обратный будет интегральным оператором (наподобие того, который возникал при доказательстве теоремы существования и единственности или при выражении решения краевой задачи через функцию Грина), и формула превращается в предел lim R(^) n интегральных операторов.
Свойство 9. Попробуем теперь выяснить, равны ли друг другу et(A+B)n etAetB jaK же^ как и в СЛучае свойства 6, напишем разложения в ряды для экспоненты от суммы 
и для произведения экспонент


Первые и вторые слагаемые этих разложений совпадают. А вот с третьим получается „загвоздка 11 : в первом разложении стоит (А + В) 2 , а во втором (если вынести множитель 1/2!) соответственно А 2 + 2АВ + В 2 . Равны ли друг другу эти выражения? Оказывается, тут не все так просто. Ведь (А + В) 2 — (А + В)(А + В) — А 2 + АВ + В А + В 2 (причем сомножители местами переставлять нельзя это же матрицы!). Так что совпадение выражений имеет место только если АВ = ВА. т.е. если матрицы А и В коммутируют.
Именно условие АВ = В А является необходимым и достаточным для того, чтобы выполнялось равенство е^ А+в ‘ 1 — e tA e tB . Необходимость мы уже показали, а для доказательства достаточности остается только произвести сравнения коэффициентов при одинаковых степенях t и воспользоваться коммутированием матриц для сведения длинных сумм во втором разложении к формуле бинома Ньютона.
Свойство 10. В теории функций комплексного переменного важную роль играет формула Коши для аналитической функции

где интегрирование производится но любому замкнутому ориентированному контуру, охватывающему точку г и оставляющему ее слева. В частности, для экспоненты f(z) — e zt

Аналогичная формула имеет место и для матричной экспоненты:

с той только разницей, что контур интегрирования должен охватывать теперь уже все собственные значения матрицы А. Эта формула, называемая формулой контурного интеграла, используется не только для вычисления экспоненты от матрицы, но и для вычисления экспоненты от дифференциального оператора. Правда, там контур интегрирования оказывается уже незамкнутым (поскольку у дифференциального оператора собственных значений может быть бесконечно много, и спектр не ограничивается никакой замкнутой кривой), точнее, замкнутым „через бесконечность 14 , и поэтому для корректного применения этой формулы необходимы довольно нетривиальные оценки роста функции (?/ — А) -1 (называемой, так же как и (/ — АЛ) -1 , резольвентой они на самом деле отличаются лишь числовым множителем) при ? —? оо но соответствующей кривой.
Задания для самостоятельной работы.
1. Найдите частные решения неоднородных систем методом неопределенных коэффициентов

2. Найдите экспоненту e At для матриц

1. Уравнение 
называется уравнением Дуффинга [2] . Попробуйте применить к этому уравнению метод неопределенных коэффициентов. При каких условиях он приводит к успеху? А если частоту у решения уменьшить в 2,3. раза?
2. Уравнение 
называется уравнением Хилла [3] . Попробуйте применить метод неопределенных коэффициентов и к нему. При каких условиях он приводит к решению? Как его модифицировать, чтобы получить решение?
Рассмотрим квадратную матрицу (A) размером (n imes n,) элементы которой могут быть как действительными, так и комплексными числами. Поскольку матрица (A) квадратная, то для нее определена операция возведения в степень, т.е. мы можем вычислить матрицы [ <= I,;; = A,>;; <= A cdot A,>;; <= cdot A,; ldots ,>; <= underbrace _ ext<к раз>,> ] где через (I) обозначена единичная матрица порядка (n.)
Составим бесконечный матричный степенной ряд [I + frac<<1!>>A + frac<<>><<2!>> + frac<<>><<3!>> + cdots + frac<<>><> + cdots ] Сумма данного бесконечного ряда называется матричной экспонентой и обозначается как (>:) [> = sumlimits_^infty
В предельном случае, когда матрица состоит из одного числа (a,) т.е. имеет размер (1 imes 1,) приведенная формула превращается в известную формулу разложения экспоненциальной функции (>) в ряд Маклорена : [ <> = 1 + at + frac<<>><<2!>> + frac<<>><<3!>> + cdots > =
Если (A) − нулевая матрица, то (> = = I;)
Если (A = I) ((I) − единичная матрица), то (> = I;)
Если для (A) существует обратная матрица (>,) то (> = I;)
(>> =
ight)A>>,) где (m, n) − произвольные действительные или комплексные числа;
Производная матричной экспоненты выражается формулой [frac<
- >left( <>>
ight) = A>.] -
Пусть (H) − невырожденное линейное преобразование. Если (A = HM>,) то (> = H>>.)
Матричная экспонента может успешно использоваться для решения систем дифференциальных уравнений. Рассмотрим систему линейных однородных уравнений, которая в матричной форме записывается в виде [mathbf‘left( t
ight) = Amathbfleft( t
ight).] Общее решение такой системы представляется через матричную экспоненту в виде [mathbfleft( t
ight) = >mathbf,] где (mathbf =
ight)^T>) − произвольный (n)-мерный вектор. Символ (^T) обозначает операцию транспонирования. В этой формуле мы не можем записать вектор (mathbf) перед матричной экспонентой, поскольку произведение матриц (mathoplimits_ Для задачи с начальными условиями (задачи Коши) компоненты вектора (mathbf) выражаются через начальные условия. В этом случае решение однородной системы записывается в виде [mathbfleft( t
ight) = >,;; ext<где>;; = mathbfleft( >
ight).] Таким образом, решение однородной системы уравнений становится известным, если вычислена соответствующая матричная экспонента. Для ее вычисления можно воспользоваться бесконечным рядом, который содержится в определении матричной экспоненты. Однако часто это позволяет найти матричную экспоненту лишь приближенно. Для решения задачи можно использовать также алгебраический способ, основанный на последнем свойстве из перечисленных выше. Рассмотрим этот способ и общий ход решения более подробно.Сначала находим собственные значения (
) матрицы (линейного оператора) (A;) Вычисляем собственные и (в случае кратных собственных значений) присоединенные векторы;
Из полученных собственных и присоединенных векторов составляем невырожденную матрицу линейного преобразования (H.) Вычисляем соответствующую обратную матрицу (>);
Находим нормальную жорданову форму J для заданной матрицы (A,) используя формулу [J = >AH.] Примечание: В процессе нахождения собственных и присоединенных векторов часто становится ясной структура каждой жордановой клетки . Это позволяет сразу записать жорданову форму без вычисления по указанной формуле.
Зная жорданову форму (J,) cоставляем матрицу (>.) Соответствующие формулы для такого преобразования выводятся из определения матричной экспоненты. Для некоторых простых жордановых форм матрица (>) имеет вид, приведенный в таблице:
( ext<Жорданова форма >J) ( ext <Матрица >>) (left( >&0\ 0&color< > end>
ight))(left( >>&0\ 0& >> end>
ight))(left( >&color1\ color0&color< > end>
ight))(left( >>&t>>>\ 0& >> end>
ight) = t>>left(
ight))(left( >&0&0\ 0&color< >&0\ 0&0&color< > end>
ight))(left( >>&0&0\ 0& >>&0\ 0&0& >> end>
ight))(left( >&color1&color0\ color0&color< >&color1\ color0&color0&color< > end>
ight))(left( >>&t>>>& >>&t>>>\ 0&0& >> end>
ight) = t>>left(
ight))Вычисляем матричную экспоненту (>) по формуле [> = H>>.]
Записываем общее решение системы, которое имеет следующий вид: [mathbfleft( t
ight) = >mathbf.] В случае систем дифференциальных уравнений (2)-го порядка общее решение выражается формулой [mathbfleft( t
ight) = left(
ight) = >left(
ight),] где (,) − произвольные постоянные.Пост написан под влиянием поста пользователя pchelintsev_an.
В данной статье я постараюсь рассказать, с какими вычислительными трудностями можно столкнуться, если пойти по «наивному» пути вычисления матричной экспоненты. Статья может быть полезна тем, кто хотел бы познакомиться с вычислительной математикой, но уже знаком с такими понятиями как система обыкновенных дифференциальных уравнений и задача Коши. Эксперименты проводились с использованием системы GNU Octave.
Что вообще такое матричная экспонента и для чего она применятеся
Матричная экспонента возникает при рассмотрении задачи Коши для линейной системы обыкновенных дифференциальных уравнений с постоянными коэффициентами:
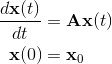
Иногда такие системы возникают после частичной дискретизации уравнений в частных производных, например, в методах конечных элементов. Тогда матрица A является некоторой конечномерной аппроксимацией дифференциального оператора. Как следствие, число строк матрицы A может легко достигать тысяч, миллионов и даже нескольких миллиардов. Такие матрицы даже невозможно хранить в виде квадратного массива, поэтому их хранят в специальных разреженных форматах представления.
Решение системы ОДУ можно выписать явно:
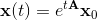
Здесь появляется матричная экспонента, которая определяется как сумма ряда:
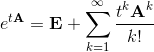
Фактически, матричная экспонента получается формальной подстановкой матрицы A в ряд Тейлора для e z (Математик отметит, что ряд сходится абсолютно для любой матрицы и любого t). Удобно то, что с помощью матричной экспоненты можно вычислить решение в любой момент времени t. Например, если эту систему решать каким-нибудь методом численного интегрирования, например, Адамса или Рунге-Кутты, то затраченное время будет пропорционально времени t. Однако, решение через матричную экспоненту возможно лишь для автономных систем с постоянными коэффициентами.
В курсе дифференциальных уравнений для практических вычислений матричной экспоненты предлагается метод приведения матрицы к жордановой форме: если матрицу A представить в виде S J S -1 , где J – жоржанова форма, S – матрица перехода к жорданову базису, то матричная экспонента А выражается через матричную экспоненту J:
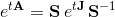
Матричная экспонента от жордановой матрицы J выписывается в явном виде. Однако такой способ требует вычисления системы собственных векторов, а также присоединенных к ним векторов. Эта задача значительно сложнее исходной. К тому же, даже для действительной матрицы А, ее жорданова форма J может быть комплексной.
Суммирование ряда
Итак, у нас есть бесконечный ряд и желание вычислить его за обозримое время. Очевидный путь – закончить суммирование на каком-то слагаемом, отбросив остаток. При этом суммирование ряда заканчивается, если очередное k-е слагаемое по норме мало:
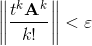
Нормы матрицы
Остановимся ненадолго на норме матрицы. Различных норм матрицы существует достаточно много. Можно ввести норму, исходя из требования
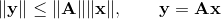
В этом случае говорят о норме матрицы индуцированной (или подчиненной) некоторой векторной норме. Для наиболее употребимых векторных норм соответствующие матричные нормы имеют вид:
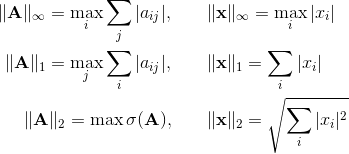
Первые две нормы матрицы считаются элементарно, а для последней требуется вычислить сингулярное число, что весьма непросто. Кроме индуцированных норм существует еще ряд других норм. Практически удобной является норма Фробениуса, которая, с одной стороны, легко вычисляется, а с другой – тесно связана с сингулярными числами А. Фактически, это евклидова норма вектора, полученного «вытягиванием» матрицы в одну строку:
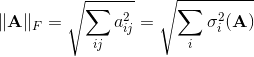
Сюрпризы при суммировании ряда
Чтобы осознать сложности, возникающие при суммировании рядов Тейлора, не обязательно обращаться к примеру с матричной экспонентой. Попробуем просто построить график функции e -x на отрезке [0, 50], суммируя аналогичным образом ряд Тейлора для экспоненты. Суммирование завершим, если очередное слагаемое не превосходит 10 -20 . Воспользуемся следующим кодом на Octave:
Результат получается довольно странным:
При x > 30 график функции начинает вести себя хаотично и не имеет с экспонентой ничего общего.
Причина данного эффекта в накоплении погрешностей округления. Например, при вычислении e -35 было просуммировано 132 слагаемых, из которых минимум абсолютной величины имело последнее слагаемое s132 ≈ 5.8674 · 10 -21 , а максимум абсолютной величины имело слагаемое с номером 35: s35 ≈ -1.067 · 10 14 . Поскольку Octave проводит вычисления с двойной точностью (примерно 16 значащих цифр), округление 35-го слагаемого уже внесло ошибку порядка 0.01, что существенно превосходит и значение ϵ = 10 -20 и само значение суммы ряда e -35 ≈ 6.305 · 10 -16
Неужели ряд Тейлора настолько безнадежен? Нет, ошибки округления не будут давать существенного вклада, если величина суммируемых слагаемых не будет достигать таких огромных значений. Например, такой алгоритм будет надежно работать при небольших значениях x (|x| ≲ 1). Для матричной экспоненты аналогичное условие имеет вид
. Кроме вычислительной устойчивости такой выбор x обеспечивает быструю сходимость, то есть достаточно взять всего несколько слагаемых из ряда для получения приемлемой точности.
Метод удвоения аргумента
Заметим, что матричная экспонента удовлетворяет следующему соотношению:
Это означает, что матричную экспоненту можно посчитать для матрицы
- Вычислить матричную экспоненту
- Умножить B на себя
- В результате,
Число p можно (и нужно) выбрать из соображений вычислительной устойчивости шага 1 алгоритма, то есть
Соответствующий Octave код:
Метод аппроксимаций Паде
Отрезок ряда Тейлора – не единственный способ приближенно вычислить значение функции. Более качественные приближения функции могут быть получены не в виде многочленов, а в виде рациональных функций. Наилучшие приближения в виде отношения двух многочленов заданных степеней называются аппроксимациями Паде. Например, аппроксимация Паде отношением двух квадратичных многочленов для экспоненты записывается в виде:
Аналогичная аппроксимация для матричной экспоненты будет иметь вид:
Аппроксимации Паде могут использоваться для шага 1 в алгоритме удвоения. Основная сложность, связанная с аппроксимациями Паде, заключается в необходимости один раз обратить матрицу. Для больших матриц это может быть довольно трудозатратно.
Анализ точности
Как убедиться, что матричная экспонента вычислена правильно? Достаточно ли, что
Вспомним, что матричная экспонента возникла не на ровном месте, а в результате решения некоторой системы обыкновенных дифференциальных уравнений. Собственные числа матрицы A характеризуют скорости процессов, протекающих в системе, описываемой данной системой дифференциальных уравнений. Например, матрица:
описывает систему с одним быстро затухающим процессом (собственное значение -1000) и двумя колебательными процессами (собственные значения ±i). Хорошим критерием правильности вычисления матричной экспоненты может являться соотношение:
связывающее собственные значения матрицы A и ее матричной экспоненты.Вычислительный эксперимент
Для начала исследуем алгоритмы на быстродействие на случайных матрицах разного размера. В качестве методов используем метод суммирования ряда Тейлора, метод удвоения аргумента и встроенную в Octave функцию expm. Изначально хотелось сравнить также соответствие собственных значений, но от этой идеи пришлось отказаться, поскольку все три алгоритма одинаково проваливали эту проверку при размерах матрицы N ≳ 50. Возможно виновником этого была функция определения собственных значений eig, работающая недостаточно точно или плохая обусловленность самой задачи определения собственных значений для этих матриц.
Исходя из графика, метод удвоения работает примерно вдвое дольше библиотечной функции (возможно стоит ослабить завышенное требование по точности), в то время как прямое суммирование имеет даже иную асимптотику ≈O(N 3.7 ), в то время, как остальные имеют асимптотику O(N 3 ).
Далее, проверим как алгоритм работает с большими по величине собственными значениями. Рассмотрим следующую систему обыкновенных дифференциальных уравнений:
С начальным условием:Её особенность в том, что одно из ее собственных значений равно -1000 (быстро затухающее решение), а два других равны ±i√2 (колебательные решения). Если в мнимые собственные значения будут внесены искажения, это будет хорошо заметно. Возьмем шаг по времени τ = 0.038, найдем матричную экспоненту
- Решение в начальный момент известно из начального условия
- Зная решение un в момент tn, решение в момент tn+1 = tn + τ получается из него умножением на матричную экспоненту B:
- Повторять второй пункт, пока не будет достигнут конец отрезка интегрирования.
Посмотрим на полученные численные траектории (отображена только первая компонента вектора):
Все траектории, кроме полученной с помощью прямого суммирования ряда Тейлора, визуально совпадают. Обратите внимание, график не выходит из начального условия x1(0) = 1. На самом деле, график экспоненциально подходит к точке y = 1, просто характерное расстояние «поворота» графика (∼ 1 / 1000) намного меньше шага по времени τ = 0.038.
Можно сказать, что пример синтетический, и на практике не встретится, однако это не так. Существует множество так называемых жестких задач Коши, которые характеризуются сильным разбросом собственных значений (по сути, скоростей физических процессов).
Дальнейшее чтение
О различных способах вычисления матричной экспоненты можно почитать в статье (англ.) [2]. По методам решения обыкновенных дифференциальных уравнений и жестких задач написан замечательный двухтомник [3,4]
- Вычислить матричную экспоненту