
401 просмотра
1 ответ
7 Репутация автора
Я использую Zabbix 3.2 для более чем 100 виртуальных машин (Windows, Linux, Mac), и я добавил скрипт для всех виртуальных машин Windows. Сценарий является локальным для каждой виртуальной машины, и agentd.conf имеет:
Он также имеет несколько других параметров пользователя, хотя это не является частью этой проблемы.
Когда я перехожу к пунктам «Предметы», присутствует красный «i», статус «Не поддерживается», а над красным «i» говорится:
Полученное значение [В настоящее время к этому удаленному компьютеру нельзя устанавливать больше соединений, поскольку количество подключений, которое может принять компьютер, уже существует] не подходит для типа значения [Числовой (без знака)] и типа данных [Десятичный].
Я нахожу это очень странным, поскольку локально наблюдать за виртуальной машиной и не использовать RDP. Я пытался использовать общую папку и иметь сценарий в 1 месте. Это явно не сработало, поэтому я делаю это локально.
В журнале написано "old_random_var не поддерживается". Это еще один параметр, который работает в zabbix, но предоставляет этот журнал. Еще раз, этот old_var совершенно не связан с var.
Использование zabbix_get говорит о том, что элемент не поддерживается.
Любой совет будет принята с благодарностью.
E: Интересное дополнение, из всех узлов, оно работает примерно в 20 случайных, а не в других. В этих узлах нет НИЧЕГО уникального. Совершенно случайно.
Ответы (1)
плюса
3091 Репутация автора
Пользовательский параметр подключается к Windows FTP. Предел подключения должен быть увеличен на стороне Windows.
Данный блог был создан как дублирование моей странички www.bubnov.su, но без всяких личных материалов – только то, что касается IT
четверг, 19 октября 2017 г.
В системе мониторинга Zabbix элемент данных vfs.file.exists[] отображает статус "не поддерживается"
3 комментария:

А триггер ты какой настроил под проверку файла?
Триггер из ленности настроил "On change" – под мою задачу хватает. хотя по идее, да, надо глубже было копнуть =)
Введение
Немного истории
Для меня описанный функционал был важен в связи с тем, что на нашем предприятии используется несколько СХД от HP, а именно HP MSA 2040/2050, метрики с которых снимаются запросами к их XML API с использованием Python-скрипта.
В самом начале, когда встала задача наблюдения за обозначенным оборудованием и был найден вариант с использованием API, выяснилось, что в самом простом случае, чтобы узнать, скажем, состояние здоровья одного компонента СХД, требовалось сделать два запроса:
- Запрос токена аутентификации (session key);
- Сам запрос, возвращающий информацию по компоненту.
Теперь представьте, что хранилище состоит из 24 дисков (а может и больше), двух блоков питания, пары контроллеров, вентиляторов, нескольких дисковых пулов и пр. — умножаем всё это на 2 и получаем более 50 элементов данных, что равно стольким же запросам к API при ежеминутных проверках. Если попробовать пойти по такому пути, API быстро «ложится», а ведь мы говорим только о запросе «здоровья» компонентов, не учитывая остальные возможные и интересные метрики — температура, наработка на часы для жестких дисков, скорость вращения вентиляторов и т.д.
Первым решением, которое я сделал чтобы разгрузить API, еще до выхода Zabbix версии 3.4, было создание кэша для получаемого токена, значение которого записывалось в файл и хранилось N-минут. Это позволило снизить количество обращений к API ровно в два раза, однако, ситуацию сильно не изменило — что-то помимо состояния здоровья получать было проблематично. Примерно в это время я посетил Zabbix Moscow Meetup 2017, устроенный компанией Badoo, где и узнал о упомянутом выше функционале зависимых элементов данных.
Скрипт был доработан до возможности отдавать подробные JSON объекты, содержащие интересующую нас информацию по различным компонентам хранилища и вывод его стал выглядеть примерно так вместо одиночных строковых или числовых значений:
Это пример с отдаваемыми данными по всем дискам хранилища. По остальным компонентам картина схожая — ключом является ID компонента, а значением — объект JSON, содержащий нужные метрики.
Всё было хорошо, но быстро всплыли нюансы, описанные в начале статьи — все зависимые метрики приходилось создавать и обновлять вручную, что было довольно мучительно (порядка 300 метрик на одну СХД плюс триггеры и графики). Нас могло бы спасти LLD, но тут, при создании прототипа, оно не позволяло нам указывать в качестве родительского айтема тот, что не был создан самим правилом, а грязный хак с созданием фиктивного айтема через LLD и подменой его itemid в БД на нужный, ронял сервер Zabbix. В багтрекере Zabbix быстро появились упомянутые фичреквесты, что указывало на то, что данный функционал важен не только мне.
Т.к. все подготовительные операции с моей стороны были завершены, я решил потерпеть и не плодить временных решений, таких как динамическая генерация шаблона и ждал только закрытия указанных в начале статьи ZBXNEXT’ов и вот совсем недавно это было сделано.
Как всё выглядит теперь
Для демонстрации новых возможностей Zabbix мы возьмем:
- СХД HPE MSA 2040 доступную по протоколу HTTP/HTTPS;
- Сервер Zabbix 4.0alpha9, установленный из официального репозитория на CentOS 7.5.1804;
- Скрипт, написанный на Python третьей версии и предоставляющий нам возможность обнаруживать компоненты СХД (LLD) и возвращать данные в формате JSON для парсинга на стороне сервера Zabbix с использованием JSON Path.
Родительский элемент данных будет представлять собой «внешнюю проверку» (external check), вызывающую скрипт с необходимыми аргументами и хранить полученные данные как текст.
Подготовка
Python-скрипт устанавливается в соответствии с документацией и имеет в зависимостях Python библиотеку «requests». Если у вас RHEL-based дистрибутив, установить её можно с помощью пакетного менеджера yum:
Или с помощью pip:
Протестировать работу скрипта можно из оболочки, запросив, например, данные LLD о дисках:
Настройка хоста
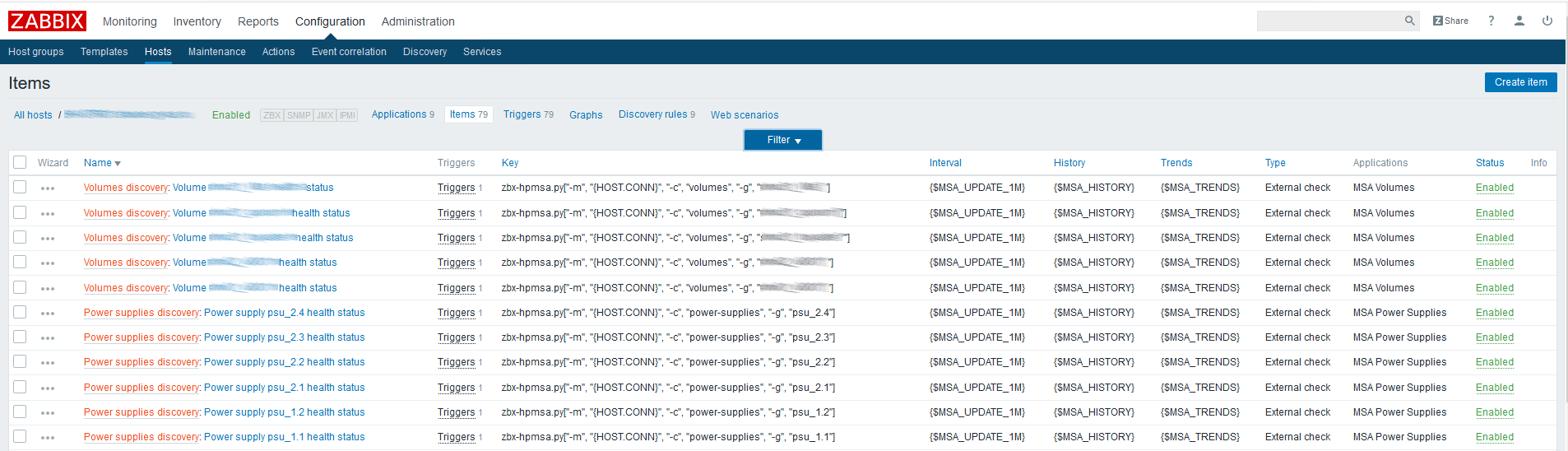
Для начала нужно создать родительские элементы данных, которые будут содержать все необходимые нам метрики. В качестве примера создадим такой элемент для физических дисков:
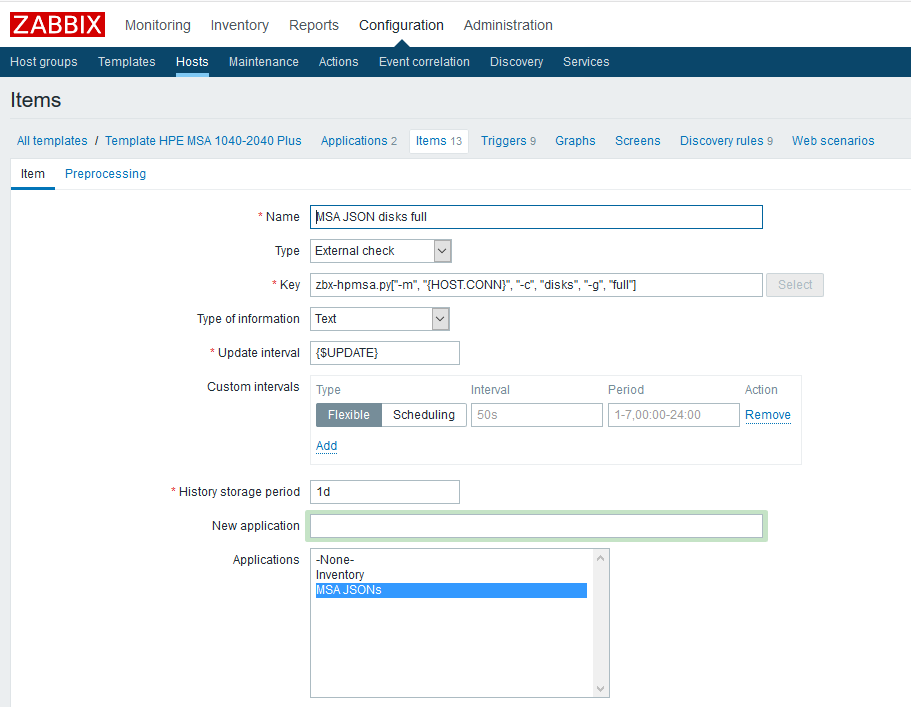
Имя — указываем произвольно;
Тип — внешняя проверка;
Ключ — вызов скрипта с нужными параметрами (см. документацию скрипта на GitHub);
Тип информации — текст;
Интервал обновления — в примере используется пользовательский макрос <$UPDATE>, разворачивающийся в значение «1m»;
Период хранения истории — один день. Думаю, что хранить родительский элемента данных дольше смысла не имеет.
Проверяем последние данные по созданному элементу:
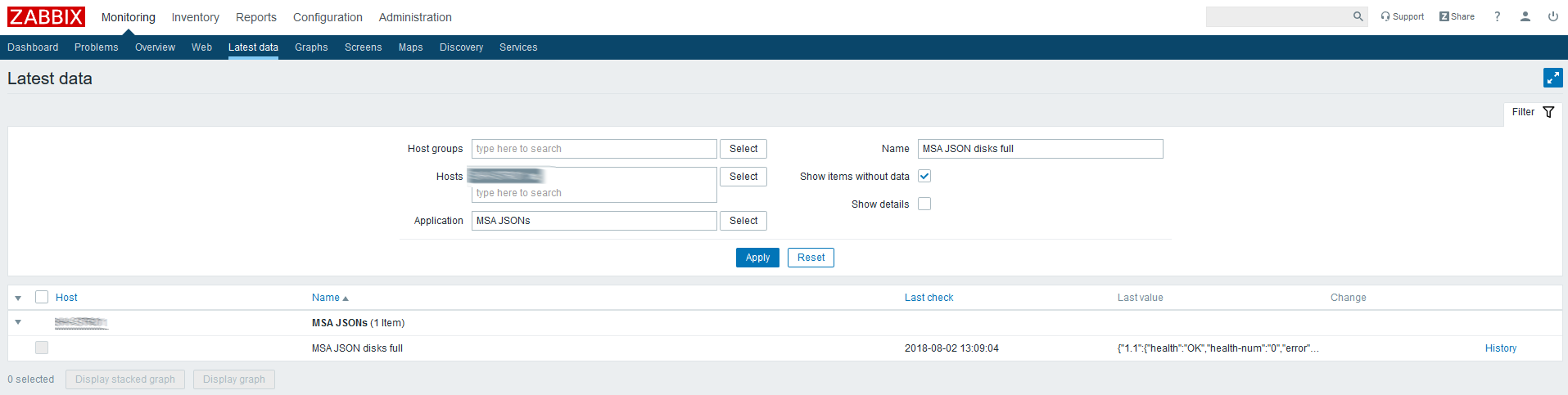
Приходит JSON, значит всё сделано правильно.
Следующим будет настройка правил обнаружения, которые отыщут все доступные для мониторинга компоненты и создадут зависимые айтемы и триггеры. Продолжая пример с физическими дисками, выглядеть оно будет так:
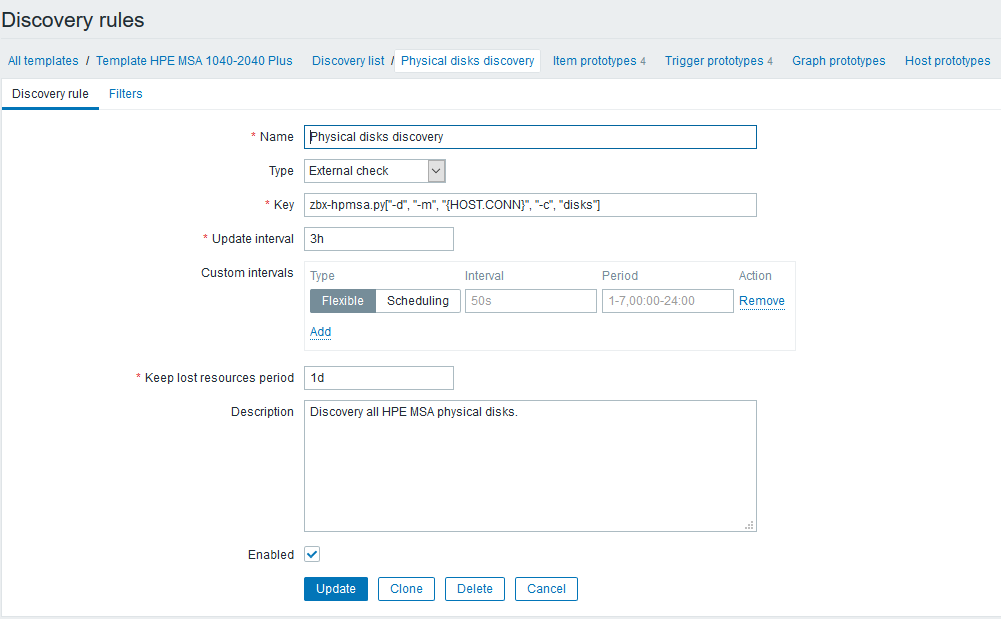
После создания правила LLD потребуется создать прототипы элементов данных. Создадим такой прототип, на примере данных о температуре:
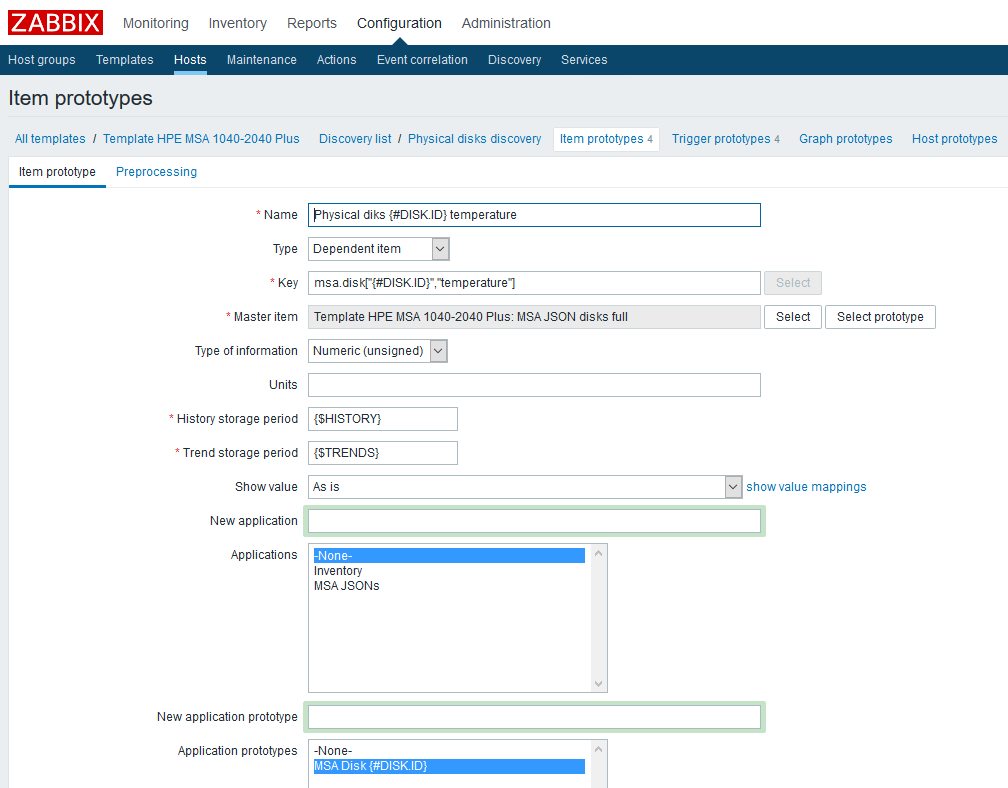
Имя — указываем произвольно;
Тип — зависимый. В качестве родительского элемента данных выбираем соответствующий созданный ранее элемент;
Ключ — проявим фантазию, но нужно учесть, что каждый ключ должен быть уникальным, поэтому включим в него макрос LLD;
Тип информации — в данном случае числовой;
Период хранения истории — в примере это пользовательский макрос, указывается по вашему усмотрению;
Период хранения трендов — опять же, пользовательский макрос;
Так же я добавил прототип «Приложения» — к нему можно удобно привязывать метрики, относящиеся к одному компоненту.
На вкладке «Препроцессинг» создадим шаг типа «JSON Path» с правилом, извлекающим показания температуры:
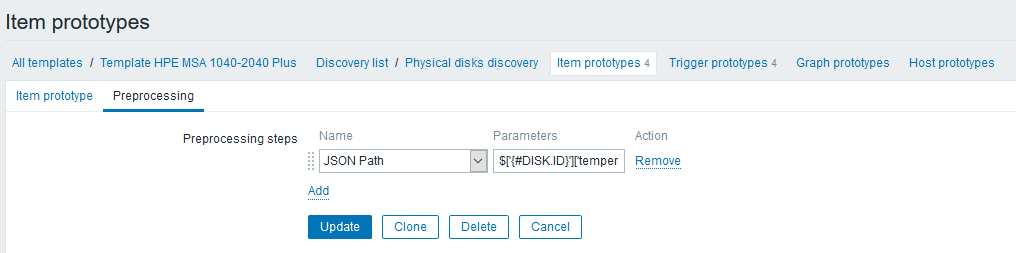
Выражение шага выглядит так: $[‘<#DISK.ID>’][‘temperature’]
Обратите внимание, что теперь в выражении можно использовать макросы LLD, что не просто значительно упрощает нам работу, но и вообще дает проделывать подобные штуки довольно просто (раньше вас бы направили в Zabbix API).
Далее, по аналогии с температурой, создадим оставшиеся прототипы элементов данных:

На этом этапе можно проверить получаемый результат, зайдя в «Последние данные» по хосту. Если там вас всё устраивает, продолжаем работу дальше. Я в итоге получил следующую картину:
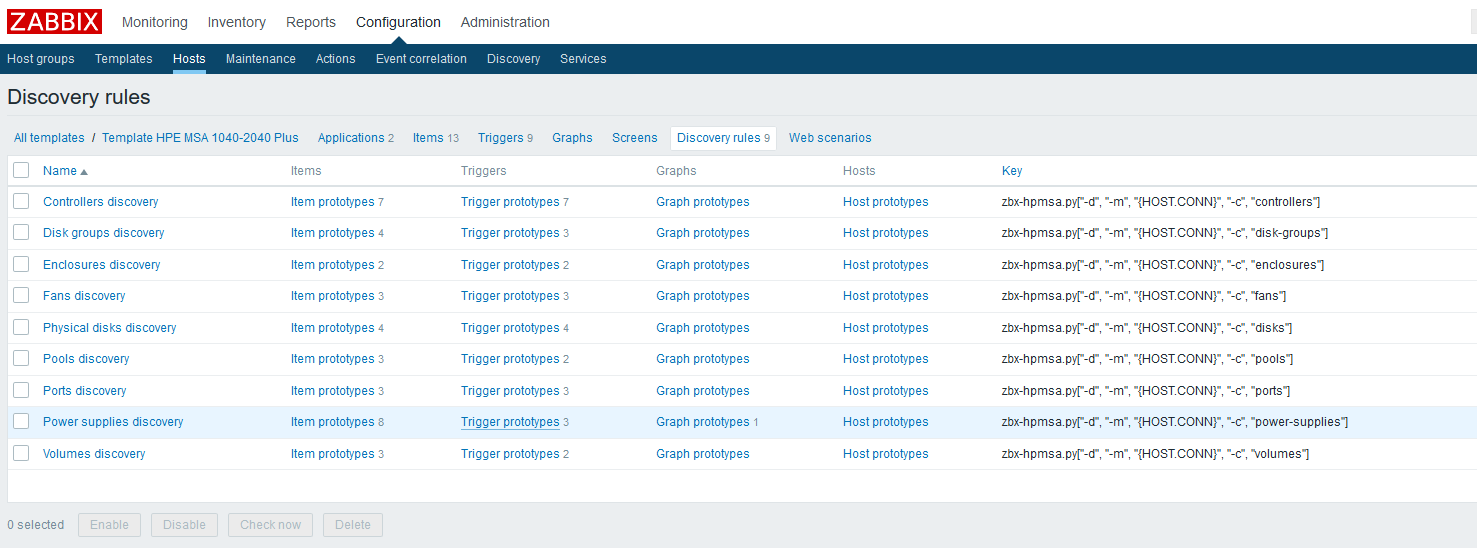
Ждем пока обновится конфигурационный кэш или толкаем его обновление вручную:
После этого можно воспользоваться еще одной крутейшей «фишкой» версии 4.0 — кнопкой «Check now» для запуска созданных правил LLD:
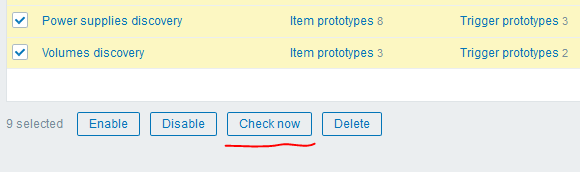
У меня получился следующий результат:
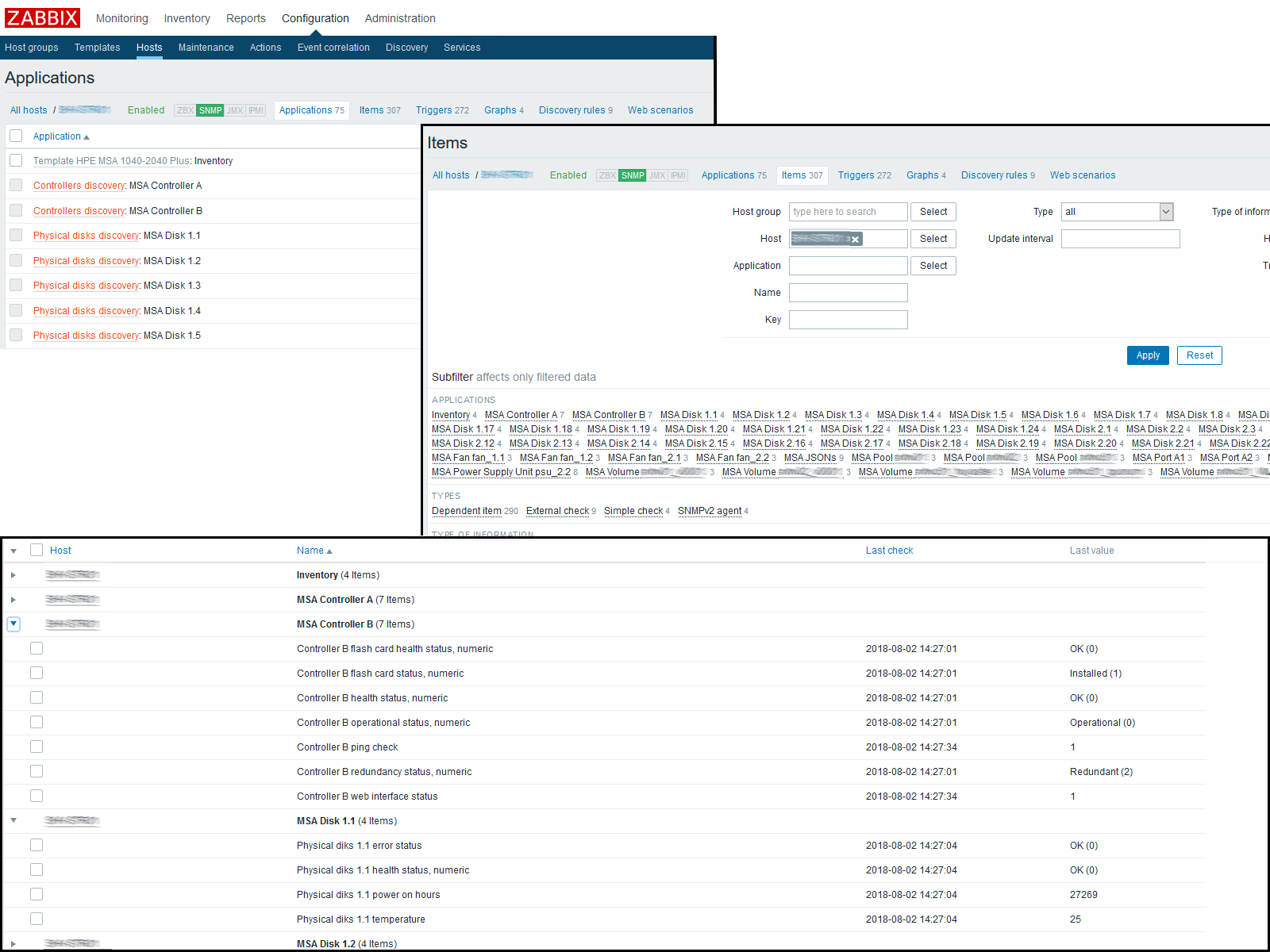
Заключение
В итоге, всего девятью запросами к XML API мы смогли получить более трехсот метрик с одного узла сети, затратив на это минимум времени и получив максимум гибкости. LLD даст нам возможность автоматически обнаруживать новые компоненты или обновлять старые.
Спасибо, что читали, ссылки на используемые материалы, а там же на актуальный шаблон для HPE MSA P2000G3/2040/2050 можно найти ниже.