
- Дизайн лендинга
- Популярное
- БД MySQL (сложные запросы, агрегатные функции, оценка производительности)
- Сравнение данных за две даты
- Подстановка нескольких значений из другой таблицы
- Вывод статистики с накоплением по дате
- Выделяют такие виды SQL запросов:
- Основные типы SQL запросов по их видам:
- Создание и настройка базы данных
- Примеры простых запросов SQL к базам данных.
- SELECT
- INSERT
- UPDATE
- DELETE
- DROP
- Примеры сложных запросов к базе данных MS SQL
- Выводы

Освойте бесплатно наиболее простой, быстрый и гибкий способ создавать адаптивные веб-сайты.
Дизайн лендинга

Создавайте дизайн любых сайтов – для себя и на заказ!
Популярное
- Главная
- ->
- Материалы
- ->
- БД MySQL (сложные запросы, агрегатные функции, оценка производительности)
Reg.ru: домены и хостинг
Крупнейший регистратор и хостинг-провайдер в России.
Более 2 миллионов доменных имен на обслуживании.
Продвижение, почта для домена, решения для бизнеса.
Более 700 тыс. клиентов по всему миру уже сделали свой выбор.
Бесплатный Курс "Практика HTML5 и CSS3"
Освойте бесплатно пошаговый видеокурс
по основам адаптивной верстки
на HTML5 и CSS3 с полного нуля.
Фреймворк Bootstrap: быстрая адаптивная вёрстка
Пошаговый видеокурс по основам адаптивной верстки в фреймворке Bootstrap.
Научитесь верстать просто, быстро и качественно, используя мощный и практичный инструмент.
Верстайте на заказ и получайте деньги.
Что нужно знать для создания PHP-сайтов?
Ответ здесь. Только самое важное и полезное для начинающего веб-разработчика.
Узнайте, как создавать качественные сайты на PHP всего за 2 часа и 27 минут!
Создайте свой сайт за 3 часа и 30 минут.
После просмотра данного видеокурса у Вас на компьютере будет готовый к использованию сайт, который Вы сделали сами.
Вам останется лишь наполнить его нужной информацией и изменить дизайн (по желанию).
Изучите основы HTML и CSS менее чем за 4 часа.
После просмотра данного видеокурса Вы перестанете с ужасом смотреть на HTML-код и будете понимать, как он работает.
Вы сможете создать свои первые HTML-страницы и придать им нужный вид с помощью CSS.
Бесплатный курс "Сайт на WordPress"
Хотите освоить CMS WordPress?
Получите уроки по дизайну и верстке сайта на WordPress.
Научитесь работать с темами и нарезать макет.
Бесплатный видеокурс по рисованию дизайна сайта, его верстке и установке на CMS WordPress!
Хотите изучить JavaScript, но не знаете, как подступиться?
После прохождения видеокурса Вы освоите базовые моменты работы с JavaScript.
Развеются мифы о сложности работы с этим языком, и Вы будете готовы изучать JavaScript на более серьезном уровне.
*Наведите курсор мыши для приостановки прокрутки.
БД MySQL (сложные запросы, агрегатные функции, оценка производительности)
В этом уроке мы поговорим о следующих моментах, касающихся работы с БД MySQL: вы узнаете, как составлять сложные запросы, как использовать агрегатные функции, объединения таблиц и как оценивать производительность запросов.
Связи в БД
Связи в БД – это ассоциативное отношение между сущностями (таблицами). В первую очередь связи позволяют избегать избыточности данных.
Избыточность же — это переполнение таблиц повторяющимися данными.
Для начала поговорим о виртуальных связях таблиц. Что представляет собой такая связь?

Таблица User_docs подчинена таблице Users, поэтому в ней есть ссылка на таблицу Users (user_id_ref).
У одного пользователя может быть как один, так и много документов. Поэтому мы выносим документы в отдельную таблицу, чтобы не повторялись данные по самому пользователю. Связь таблиц User и User_docs – “один-ко-многим”.
Внимание! Впредь, если подразумевается, что некоторые данные могут дублироваться, стоит их выносить в отдельную таблицу.
Запрос из двух таблиц
Функциональность MySQL не ограничивается запросом вида SELECT * FROM table. Это самый простой запрос. Такого запроса достаточно, если весь необходимый набор данных содержится в одной таблице. Но мы учимся правильно проектировать БД, поэтому и запросы у нас будут несколько сложнее и функциональнее.
Предлагаю данный момент разобрать на примерах Интернет-каталога.
Допустим, у нас задача, реализация каталога продукции в сети Интернет. Что для этого нужно сделать? Для начала спроектируем базу данных. Для этого нужно определиться с основными сущностями будущей БД. Первая и основная сущность – это Продукт. Создадим таблицу Products:
В этой таблице мы будем хранить наши продукты. Как вы заметили, я заранее добавил в таблицу поле Group_id_ref. Это поле привязывает продукт к конкретной группе. Создадим таблицу групп товаров:
Кроме того, часто встречается ситуация, когда товары имеют дополнительные свойства, такие как Цвет, Размер и пр.
Добавим таблицу Colors:
И таблицу Sizes (Размеры):
Теперь мы можем хранить все наши данные по Продукту. Заполним таблицы тестовыми данными.
Теперь мы имеем все данные для одного продукта. Но ведь не всегда у всех товаров должны быть все возможные реквизиты цвета и размера. Иногда бывают костюмы маломерки, иногда наоборот.
Добавим таблицы, связывающие товары с реквизитами:
В этой таблице мы будем хранить реквизиты для каждого продукта. Добавим тестовые данные:
Теперь наш тестовый продукт имеет два реквизита: Цвет и Размер.
Поясню, как так получилось. Для этого рассмотрим таблицу Product_values. В этой таблице нет никаких текстовых записей, присутствуют только идентификаторы.
– Record_id – уникальный идентификатор нашей таблицы. В прошлой статье я указывал на необходимость этого поля.
– Product_id_ref – ссылка на продукт. Собственно “_ref” и указывает на то, что это ссылка – reference. Идентификатор товара в таблице Products (мы учимся связывать именно с помощью идентификаторов).
– Value_id_ref – Ссылка на реквизиты товара.
– Value_type – Тип реквизита. 1- цвет, 2- размер и пр., если у вас таковые будут.
Давайте посмотрим, как построить запрос, чтобы получить наши данные. Сначала получим список групп. Обычно в каталогах дерево продуктов начинается именно с групп.
Тут все просто. При помощи Group_id мы формируем ссылку на список товаров в группе. Формировать ссылку можно как в запросе, так и в скрипте, на котором написан ваш каталог.
Результат выборки выглядит так:

В каталоге на сайте такую выборку можно использовать в списке товаров. Product_id используем для формирования ссылки на конкретный товар.
Для конкретного товара запрос будет похожим, за исключением того, что мы укажем p.Product_ >
Немного поясню, что такое «р.» в данном запросе. Для СУБД запрос вида:
То есть всегда поле указывается с таблицей. В принципе, имя таблицы можно не писать, если поля ВО ВСЕХ(!) таблицах запроса именуются по-разному.
Но такой идеальной ситуации, как правило, не бывает и логичнее указывать не имя таблицы а ее алиас.
В этом случае p – это Products, а g – это Product_groups. Теперь в запросе нет необходимости писать имя таблицы целиком, достаточно описать только алиас.
Внимание! В громоздких запросах алиасы значительно ускоряют написание. Так же такой подход к написанию запроса более корректен.
Итак, для конкретного товара запрос будет таковым:
Теперь получим реквизиты товара. Список расцветок получаем запросом:

Подобным запросом получим и размеры.
Немного поясню запрос.
v.value_type = 1 — указываем тип реквизита. С типами нужно заранее определиться и, при добавлении товара, добавлять реквизит с соответствующим типом.
Запросы с JOIN
JOIN — оператор языка SQL, который является реализацией операции соединения реляционной алгебры. Входит в раздел FROM операторов SELECT, UPDATE или DELETE. Используется при связке двух или более таблиц.
Такое объединение выдаст нам набор записей, в котором данные таблицы Colors присутствуют в таблице Product_values. То есть только те записи, которые удовлетворяют условию c.color_ >
Но бывают такие случаи, когда нам нужно получить все данные из одной таблицы и только те данные из второй таблицы, которые присутствуют в первой. Рассмотрим на примере.
Допустим, для товаров мы будем хранить фото. Создадим таблицу для фотографий.
Представим условие, что не у всех товаров есть фото и напишем запрос для получения списка товаров с фото.
Результат выборки следующий:

Как мы видим, у товара нет фотографии. NULL означает пусто.
Но, когда мы в скриптовом языке (PHP и пр.) будем выводить список, и в тег img попадет пустое значение, фото в браузере будет потеряно.
Модифицируем запрос для того, чтобы избежать этого:
IFNULL обрабатывает как раз значение NULL. Если значение пустое, можем подставить свое значение. В данном случае мы подставим «empty.jpg». Для корректного отображения на странице добавим на сайт изображение empty.jpg и теперь мы имеем красивый список.
Внимание! Старайтесь всегда обрабатывать значения NULL. Не стоит такого рода логику обрабатывать на клиентском приложении, запросами она обрабатывается значительно легче.
Теперь непосредственно про LEFT JOIN. Так называемое «левое объединение» выводит все данные основной таблицы и только те данные второй, которые удовлетворяют условию блока ON.
Есть также RIGHT и FULL JOIN. RIGHT, по сути, аналогичен LEFT, только запрос выведет все данные второй таблицы и те записи первой, которые удовлетворяют условию блока ON.
Можно всегда использовать LEFT, только менять местами таблицы.
FULL JOIN выведет все данные обеих таблиц, но практическую реализацию подобного запроса встретишь довольно редко.
Агрегатные функции
В этой части мы перейдем от простого использования запросов к извлечению значений из базы данных и определению, как вы можете использовать эти значения чтобы получить из них информацию.
Это делается с помощью агрегатных или общих функций, которые берут группы значений из поля и сводят их до одиночного значения. Вы узнаете, как использовать эти функции, как определить группы значений, к которым они будут применяться, и как определить, какие группы выбираются для вывода.
Запросы могут производить обобщенное групповое значение полей точно так же, как и значение одного поля. Это делается с помощью агрегатных функций. Агрегатные функции производят одиночное значение для всей группы таблицы. Список этих функций:
COUNT — выводит количество полей, которые выбрал запрос;
SUM — выводит арифметическую сумму всех выбранных значений данного поля;
MAX — выводит наибольшее из всех выбранных значений данного поля;
MIN — выводит наименьшее из всех выбранных значений данного поля;
AVG — выводит усреднение всех выбранных значений данного поля.
При написании запросов с агрегатными функциями, необходимо научиться правильным образом организовать группировку (GROUP BY).
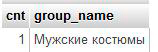
Пример запроса с группировкой:
Запрос выведет нам список групп и количество товаров в каждой:
Остальные агрегатные функции работают аналогично, и запросы выглядят идентично:
Запрос выведет нам список групп и общую стоимость товаров в каждой.
Внимание! Агрегатные функции используются только в блоке SELECT. Если мы хотим добавить агрегатную функцию в блок WHERE, нужно использовать команду HAVING.
Запрос выведет имена тех групп, в которых более одного товара. Таким же образом пишутся запросы с условием других агрегатных функций.
Оценка производительности запросов
Тут все настолько просто, насколько сложно. Для оценки производительности необходимо перед запросом добавить EXPLAIN EXTENDED.
Тогда, при выполнении запроса, мы получим план запроса. Для простых запросов данная процедура не требуется, поэтому рассматривать производительность необходимо только на крупных запросах.

Я преднамеренно убрал все индексы из запроса, чтобы план показал, что запрос неэффективен.
Значения полей possible_keys, key, key_len и ref не заполнены. Такой результат нас не устраивает. Поэтому добавим индексы на колонки Product_photos.product_id_ref и Products.product_id.
Внимание! Не стоит перегружать таблицу индексами. От того, что таблица будет вся проиндексирована, запрос не будет выполняться быстрее. К тому же размер индекса будет сопоставим с размерами таблицы.
Итог
В данной статье мы изучили:
– Связи в БД
– Запросы из двух и более таблиц
– Запросы с JOIN
– Агрегатные функции
– Оценку производительности запросов
Текущего набора знаний вполне достаточно, чтобы делать большие интернет проекты с использованием БД. Для себя вы можете доработать БД индексами и триггерами.
Материал подготовил Владимир Миняйлов специально для сайта CodeHarmony.ru
Исходники:
P.S. Хотите углубить свои знания и навыки? Присмотритесь к премиум-урокам по различным аспектам сайтостроения, включая SQL и работу с БД, а также к бесплатному курсу по созданию своей CMS-системы на PHP с нуля.
Понравился материал и хотите отблагодарить?
Просто поделитесь с друзьями и коллегами!
Всего лишь пару лет назад, в проектах, которые предусматривали работу с базами данных и построением статистики, основным изобилием используемых SQL-запросов, преобладало в основном множество запросов, ориентированных на стандартную выборку данных и нечасто можно было увидеть другие, которые безо всяких сомнений можно было бы отнести к “эксклюзиву”. Хотя сложность запроса и зависит от количества используемых таблиц, но если мы всего лишь возьмем и выведем данные полей трех или более таблиц имеющих стандартное объединение, то явная сложность такого запроса не выйдет за пределы стандартной.
В данной статье по мере возможности будут рассматриваться те запросы, примеры которых мне найти не удалось и которые, по моему мнению, не относятся к классу простых.
Сравнение данных за две даты
Хотя данная статистика из рода задач довольно редко встречаемых, но все-таки необходимость в ее получении иногда существует. И получить такую статистику ничуть не сложнее других.
Работать мы будем с двумя таблицами, структура которых представлена ниже:
Структура таблицы products
Структура таблицы statistics
Дело в том, что стандарт языка SQL допускает использование вложенных запросов везде, где разрешается использование ссылок на таблицы. Здесь вместо явно указанных таблиц, благодаря использованию псевдонимов, будут применяться результирующие таблицы вложенных запросов с имеющейся связью один – к – одному. Результатом каждой результирующей таблицы будут данные о количестве произведенных заказов некоего товара за определенную дату, полученные путем выполнения запроса на выборку данных из таблицы statistics по требуемым критериям. Иными словами мы свяжем таблицу statistics саму с собой. Пример запроса:
В итоге имеем такой результат:
Подстановка нескольких значений из другой таблицы
Необходимость в данном запросе не является повседневной, но возникает не совсем уж и редко. Самый распространенный пример, это обычная сетевая игра. Где создается сессия на два игрока. Соответственно в таблице с данными об играх имеются два поля с идентификаторами зарегистрированных игроков. Для того чтобы вывести информацию об имеющихся играх, мы не можем обойтись стандартным объединением таблицы с данными об игроках и таблицы об имеющихся играх. Так как мы имеем два поля с идентификаторами неких игроков. Но мы можем обратиться опять за помощью к псевдонимам таблиц.
Демонстрация данного запроса будет происходить на другом примере, а не на примере сетевой игры. Это чтобы не создавать заново все необходимые таблицы. В качестве данных возьмем таблицу products из примера “сравнение данных за две даты” и создадим еще одну недостающую таблицу replace_com, структура которой представлена ниже:
Предположим, что у нас есть некий компьютерный салон и мы проводим модификации некоторых компьютерных составляющих, а все операции по замене комплектующих заносим в базу данных. В таблице replace_com интересующими нас полями являются: sProductID и rProductID. Где sProductID – идентификатор заменяемого модуля, а rProductID – идентификатор заменяющего модуля. Запрос, реализующий вывод данных о совершенных операциях выглядит следующим образом:
Результирующая таблица данных:
Вывод статистики с накоплением по дате
Предположим, что у нас имеется склад с некими товарами. Товары периодически поступают, и нам бы хотелось видеть в отчете остатки товаров по дням. Поскольку данные о наличии товаров необходимо накапливать, то мы введем пользовательскую переменную. Но есть одно небольшое “но”. Мы не можем использовать в запросе переменные пользователя и группировку данных одновременно (вернее можем, но в итоге получим, не то, что ожидаем), но мы можем использовать вложенный запрос, вместо явно указанной таблицы. Данные в таблице будут предварительно сгруппированы по дате. И уже затем на основе этих данных мы произведем расчет статистики с накоплением.
На первом этапе требуется установить переменную и присвоить ей нулевое значение:
В следующем запросе, мы созданную ранее переменную и применим:
Получить используемую в примерах базу данных можно здесь.

Каждый сайт в Интернете, любой проект, обрабатывающий значительный объем информации, вынужден хранить эту информацию в тех или иных базах данных (БД). Подавляющее большинство проектов информацию сохраняют в БД реляционного типа, делая записи в различных подобиях таблиц. Как внесение новых записей, так и обращение к имеющимся, осуществляется с благодаря использованию запросов, составляемых конструкциями SQL (structured query language) – непроцедурного декларативного языка структурированных запросов. В нашем случае это подразумевает, что, используя конструкции SQL, мы будем обращаться к БД, сообщая что нужно сделать с данными, но не указывая способ, как именно это нужно сделать.
Фактически, SQL является набором стандартов, для написания запросов к БД. Последняя действующая редакция стандартов языка SQL – ISO/IEC 9075:2016.
Основываясь на указанных стандартах языка SQL, ряд организаций выпустили свои, расширенные версии стандартов указанного языка. Подобные версии иногда называют диалектами SQL.
Варианты спецификаций SQL разрабатываются компаниями и сообществами и служат, соответственно, для работы с разными СУБД (Системами Управления Базами Данных) – системами программ, заточенных под работу с продуктами из своей инфраструктуры.
Наиболее применяемые на сегодня СУБД, использующие свои стандарты (расширения) SQL:
MySQL – СУБД, принадлежащая компании Oracle.
PostgreSQL – свободная СУБД, поддерживаемая и развиваемая сообществом.
Microsoft SQL Server – СУБД, принадлежащая компании Microsoft. Применяет диалект Transact-SQL (T-SQL).
Благодаря тому, что диалекты SQL что создаются, специфицируются и используются разными организациями, имеют как общие черты, так и ряд отличий в возможностях расширений.
Общими чертами диалектов являются основные конструкции, применимые практически без отличий во многих реляционных БД. Основные отличия диалектов состоят в различиях использованных типов данных, количеством, реализацией и детальными возможностями команд. Разные диалекты применяют как разные наборы зарезервированных слов, так и разные наборы команд.
Здесь мы будем рассматривать запросы, применяя конструкции из спецификаций диалекта T-SQL.
Коснемся классификации SQL запросов.
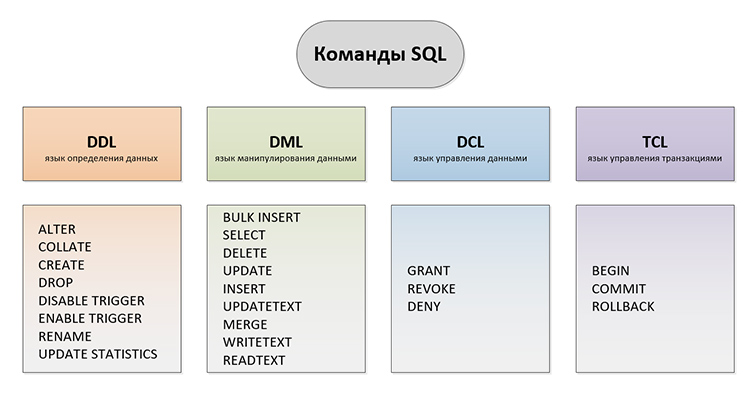
Выделяют такие виды SQL запросов:
DDL (Data Definition Language) – язык определения данных. Задачей DDL запросов является создание БД и описание ее структуры. Запросами такого вида устанавливаются правила того, в каком виде различные данные будут размещаться в БД.
DML (Data Manipulation Language) – язык манипулирования данными. В число запросов этого типа входят различные команды, используя которые непосредственно производятся некоторые манипуляции с данными. DML-запросы нужны для добавления изменений в уже внесенные данные, для получения данных из БД, для их сохранения, для обновления различных записей и для их удаления из БД. В число элементов DML-обращений входит основная часть SQL операторов.
DCL (Data Control Language) – язык управления данными. Включает в себя запросы и команды, касающиеся разрешений, прав и других настроек СУБД.
TCL (Transaction Control Language) – язык управления транзакциями. Конструкции такого типа применяют чтобы управлять изменениями, которые производятся с использованием DML запросов. Конструкции TCL позволяют нам производить объединение DML запросов в наборы транзакций.
Основные типы SQL запросов по их видам:
Ниже мы рассмотрим практические примеры применения SQL запросов для взаимодействия с БД используя запросы двух категорий – DDL и DML.
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.
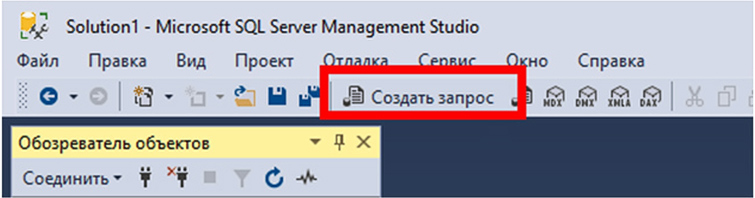
Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
Создадим новую БД с именем «b_library» для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library».
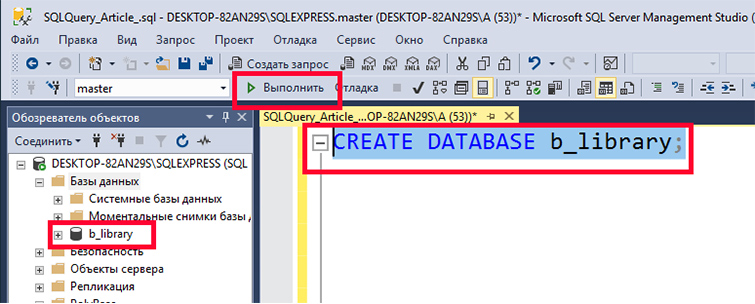
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
В БД «b_library» создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
Мы можем посмотреть в «tAuthors» записи, путем отправления в СУБД простого SQL запроса:
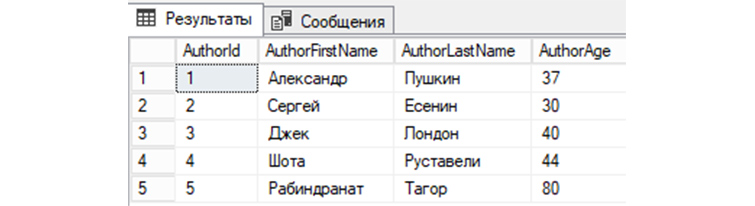
В нашей БД «b_library» мы создали первую таблицу «tAuthors», заполнили «tAuthors» авторами книг и теперь можем рассмотреть различные примеры SQL запросов, которыми мы сможем взаимодействовать с БД.
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
SELECT
1) Выведем все имеющиеся у нас БД:
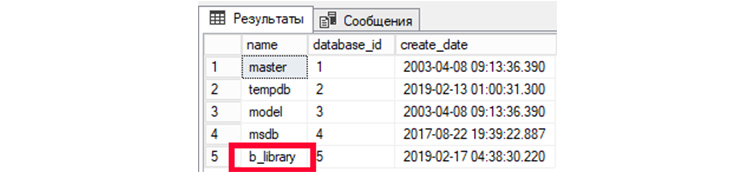
2) Выведем все таблицы в созданной нами ранее БД «b_library»:

3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
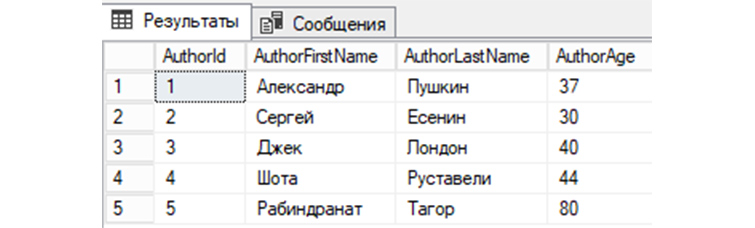
4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:

5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):

6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
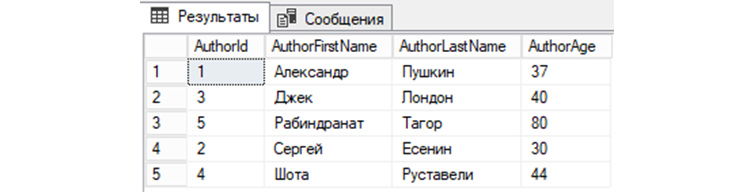
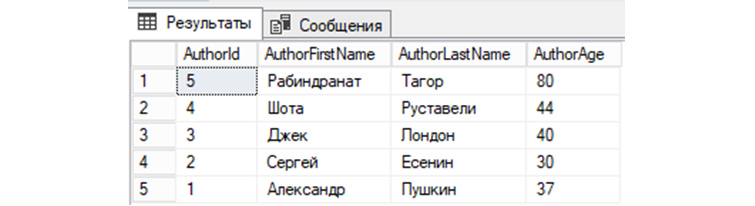
7) Выведем из «tAuthors» данные, предварительно по AuthorId отсортировав их по убыванию:
8) Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:

9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:

10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:

11) Сделаем выборку всех строк из «tAuthors», значение AuthorId в которых равняется 2 или 4:

12) Выберем в «tAuthors» такую запись AuthorAge, значение которой – наибольшее:

13) Проведем выборку из «tAuthors» по столбцам AuthorFirstName и AuthorLastName:
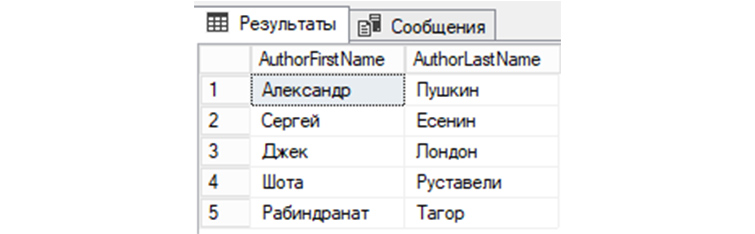
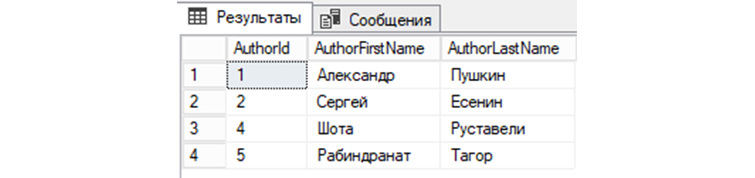
14) Получим из «tAuthors» все строки, у которых AuthorId не равняется трем:
INSERT
INSERT – это вид запроса SQL, при применении которого СУБД выполняет добавление новых записей в БД.
Добавим в «tAuthors» нового автора – Уильяма Шекспира, 51 год. Соответственно в поле AuthorFirstName добавится Уильям, в AuthorLastName добавится Шекспир, в AuthorAge – 51. В AuthorId, в нашем случае, автоматически добавится значение, инкрементированное от предыдущего на 1.
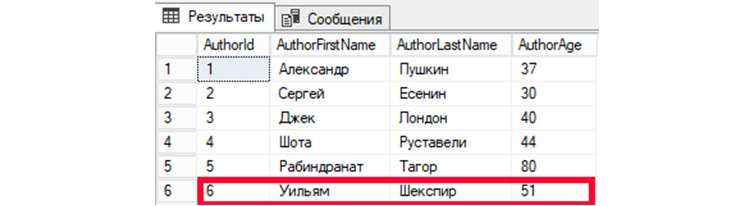
UPDATE
UPDATE – SQL запрос, позволяющий внести изменения или дописывать новую информацию в те записи, которые уже существуют.
Внесем корректировки в шестую запись (Author >
Затем, обратимся к БД, чтобы вывести все имеющиеся записи:
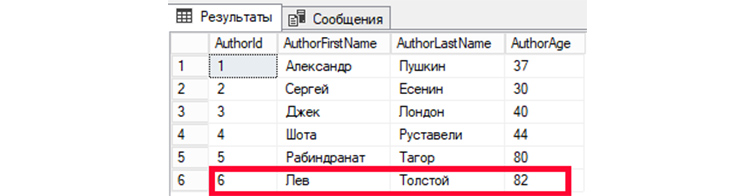
Мы видим изменения информации в записи автора под номером 6.
DELETE
DELETE – SQL запрос, выполняя который в СУБД производится операция удаления определенной строки из таблицы в БД.
Обратимся к «tAuthors» с командой на удаление строки, где Author >
Чтобы увидеть изменения, снова обратимся к базе для вывода всех записей:
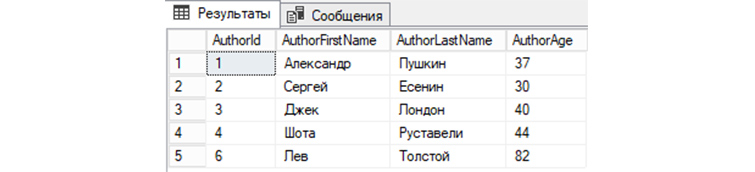
Мы видим, что запись автора под номером 5 теперь отсутствует в «tAuthors» и, соответственно, не выводится с другими записями.
DROP
DROP – ключевое слово в SQL, применяемое для удаления данных с помощью запроса. К примеру удаление некоторой таблицы из БД.
После рассмотрения ряда простых запросов к БД мы можем полностью удалить нашу таблицу «tAuthors» целиком, выполнив простой SQL запрос:
Далее рассмотрим сложные запросы SQL.
Примеры сложных запросов к базе данных MS SQL
Сложные запросы SQL представляют из себя комбинации простых запросов. Выполняясь, простые запросы возвращают сгруппированные в промежуточные таблицы наборы данных. А сложный запрос уже манипулирует данными, полученными благодаря простым «подзапросам».
Сложные запросы получаются следующими способами:
- Помещением одного запроса в другой. В этом случае внешнее выражение будет называться основным запросом, а вложенное выражение – подзапросом.
- Применение с SQL запросами различных операторов объединения результатов выполнения подзапросов. Такие операторы называют реляционными.
Рассмотрим в SQL примеры сложных запросов.
Воспользуемся нашей предыдущей таблицей «tAuthors» и создадим дополнительно еще одну таблицу с книгами этих авторов – «tBooks». В качестве идентификатора авторов книг используем значение AuthorId из «tAuthors», а название книги – BookTitle.
Заполним «tBooks» такими книгами:
1) Сделаем выборку из БД всех книг, у которых имя автора – «Александр»:

2) Сделаем выборку данных из «tBooks» всех книг, авторами которых являются люди, с именами «Александр» или «Сергей»:
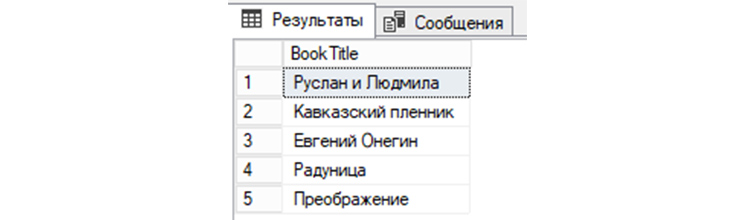
3) Сделаем выборку по книгам из таблицы «tBooks», у которых именами авторов являются НЕ «Сергей» и НЕ «Александр»:

4) Возьмем таблицу «tBooks» и сделаем из нее выборку всех книг с указанием как имен, так и фамилий авторов этих книг из «tAuthors»:
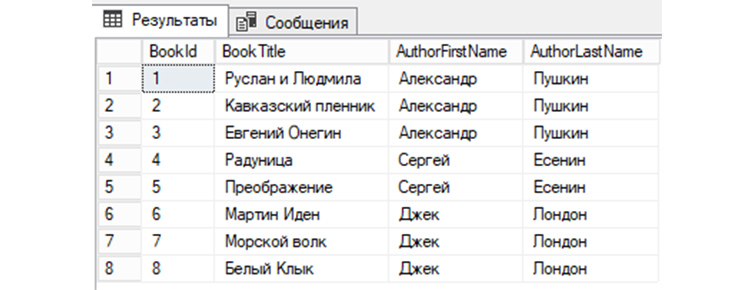
Выводы
Мы с вами рассмотрели несколько вариантов простых и сложных SQL запросов. Конечно эту статью не стоит рассматривать ни как учебное пособие, ни как исчерпывающий перечень возможностей запросов в T-SQL, и других диалектах. Скорее ее можно считать примером SQL запросов для начинающих. Однако она может послужить для Вас отправной точкой.